数据库读写分离
一、读写分离
1.1 定义
数据库读写分离是一种通过将 读操作(SELECT) 与 写操作(INSERT/UPDATE/DELETE) 分配到不同数据库实例的架构设计模式,旨在优化性能并提升系统可用性。
1.2 核心价值
- 性能提升:分散读压力,避免单点瓶颈(如电商商品浏览与订单提交分离)。
- 高可用性:主库故障时,从库可切换为主库继续服务。
- 扩展性:通过增加从库应对突发读流量(如促销活动期间的查询高峰)。
二、核心原理与架构设计
2.1 主从分工模型
| 角色 | 职责 | 特点 |
|---|---|---|
| 主库 | 处理所有写操作及DDL语句 | 高写入性能,需配置二进制日志 |
| 从库 | 处理读操作,通过复制同步数据 | 支持多从库负载均衡 |
2.2 数据同步机制
- 异步复制:主库提交事务后立即返回,从库异步同步(默认模式,性能高但存在延迟)。
- 半同步复制:主库提交事务后需等待至少一个从库确认(平衡一致性与性能)。
- 全同步复制:主库提交需所有从库确认(强一致性,但性能最低)。
2.3 架构图示例
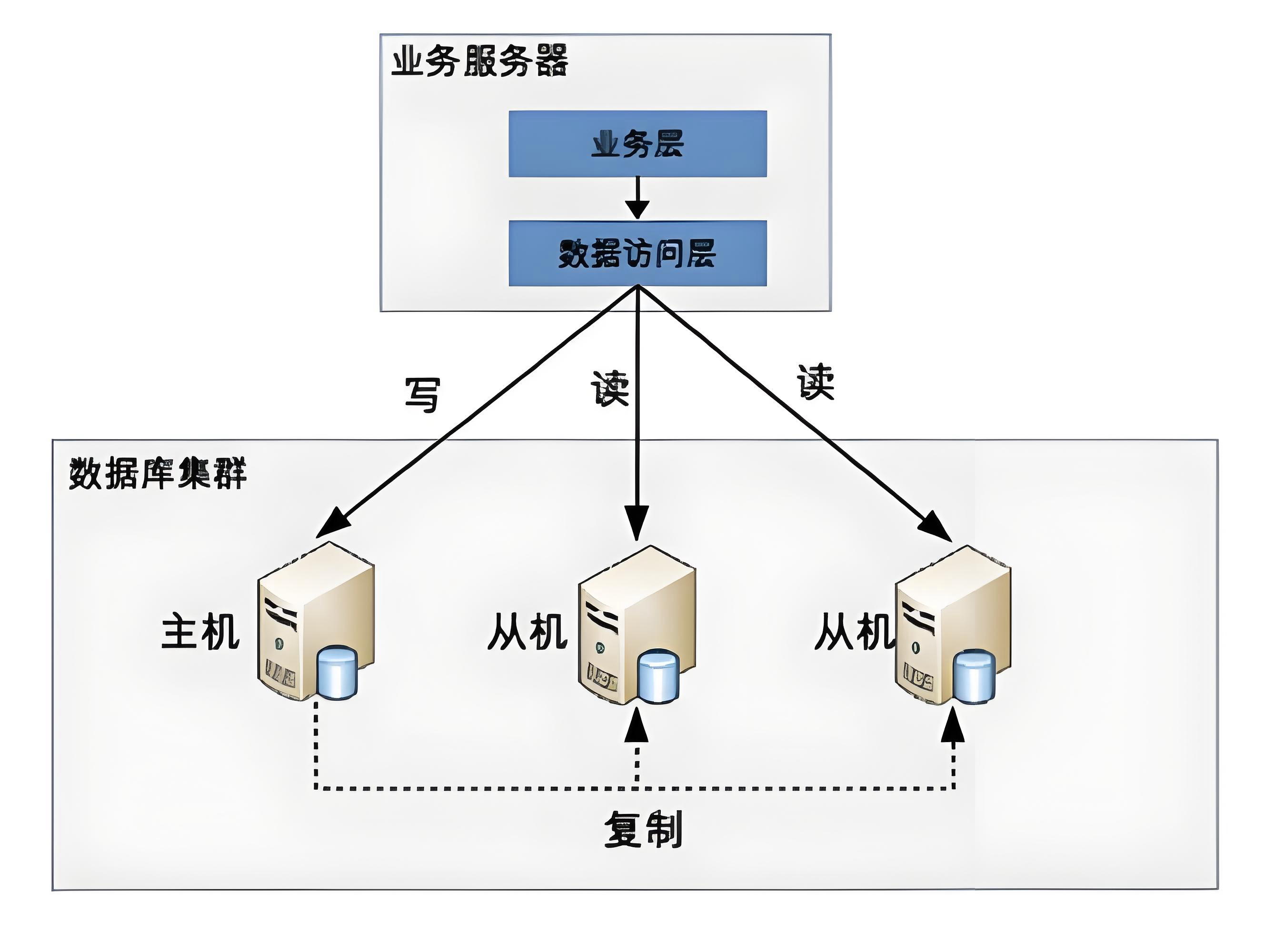
三、技术实现方案
3.1 中间件方案
3.1.1 主流中间件对比
| 中间件 | 开发背景 | 支持事务 | 负载均衡 | 适用场景 |
|---|---|---|---|---|
| MyCAT | 开源社区 | 支持 | 支持 | 复杂分库分表、读写分离 |
| ProxySQL | Percona | 支持 | 支持 | 高性能MySQL代理 |
| MaxScale | MariaDB | 支持 | 支持 | MariaDB生态集成 |
3.1.2 配置示例(以MyCAT为例)
- 主库配置(
my.cnf):[mysqld] server-id=1 log-bin=mysql-bin binlog_format=ROW - 从库配置(
my.cnf):[mysqld] server-id=2 relay-log=mysql-relay-bin read_only=1 - MyCAT路由规则(
schema.xml):<schema name="test_db" dataNode="dn1"> <table name="user" dataNode="dn1" rule="mod-user-id"/> </schema> <dataNode name="dn1" dataHost="hostM1,hostS1,hostS2"/>
3.2 应用层方案
3.2.1 代码封装(Java示例)
public class DataSourceRouter {
private static final ThreadLocal<Boolean> isWriteOperation = new ThreadLocal<>();
public static void setWriteMode() {
isWriteOperation.set(true);
}
public static DataSource determineDataSource() {
return isWriteOperation.get() ? masterDataSource : slaveDataSource;
}
}
3.2.2 Spring AOP实现
@Aspect
@Component
public class ReadWriteSplitAspect {
@Around("execution(* com.example.service.*Service.*(..))")
public Object route(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
if (method.isAnnotationPresent(ReadOnly.class)) {
DataSourceContextHolder.setSlave();
} else {
DataSourceContextHolder.setMaster();
}
try {
return joinPoint.proceed();
} finally {
DataSourceContextHolder.clear();
}
}
}
四、关键问题与解决方案
4.1 主从延迟问题
| 场景 | 解决方案 | 原理说明 |
|---|---|---|
| 用户注册后立即登录 | 强制读主库 | 写操作后标记会话,后续读请求走主库 |
| 报表统计 | 异步补偿 + 缓存 | 允许秒级延迟,通过定时任务同步数据 |
| 金融交易 | 分布式事务(Seata/TCC) | 保证跨库操作的原子性 |
4.2 主库故障切换
- 手动切换:
-- 停止主库写入 SET GLOBAL read_only = ON; -- 提升从库为主库 STOP SLAVE; RESET SLAVE ALL; - 自动切换(MHA):
- 监控主库心跳
- 自动选举新主库
- 更新客户端路由配置
五、适用场景与最佳实践
5.1 推荐场景
- 电商系统:商品浏览(读)与订单提交(写)分离
- 日志分析:实时日志写入主库,历史日志分析从库
- 社交平台:用户动态写入主库,粉丝列表读取从库
5.2 反模式警示
- 跨库JOIN查询:导致性能下降,需业务层拆分
- 强一致性要求:金融交易等场景需额外保障机制
- 从库过载:需动态调整读权重,避免雪崩效应
六、实战案例演示
6.1 环境准备
- 主库:192.168.1.100(MySQL 8.0)
- 从库:192.168.1.101(MySQL 8.0)
- 中间件:MyCAT 1.6.7
6.2 配置流程
-
主从复制搭建:
-- 主库创建复制用户 CREATE USER 'repl'@'%' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'; -- 从库配置复制 CHANGE MASTER TO MASTER_HOST='192.168.1.100', MASTER_USER='repl', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154; START SLAVE; -
MyCAT路由配置:
<dataHost name="cluster" maxCon="1000" writeType="0"> <heartbeat>SELECT 1</heartbeat> <writeHost host="master" url="192.168.1.100:3306"/> <readHost host="slave1" url="192.168.1.101:3306"/> </dataHost>
0